Les étapes du workflow ML
L'intelligence artificielle n'est plus un mythe, elle est devenue une réalité. Les machines sont capables d'affectuer des tâches initialement réservées aux humains et cela est possible grâce à l'apprentissage, c'est tout l'objet du machine learning. Dans cette formation, je vous propose de découvrir les notions fondamentales du machine learning et la librairie Scikit-learn de l'INRIA.

I. Collecte des données#
Le carburant qui fait tourner la machine#
Les données sont essentielles et nécessaires à la résolution d’un problème avec les techniques de machine learning. Ces données peuvent être déjà existantes ou non. Si vous n'avez pas les données à disposition alors il faudra les collecter. Sans quoi, les techniques de machine learning ne seront d’aucune utilité.
PAS DE DONNÉES, PAS DE MACHINE LEARNING

Où trouver les données ?#
Les données peuvent provenir de sources différentes:
- Bases de données de l’entreprise
- Les archives
- En ligne sur Internet
- Colleter sur le terrain
- Commander un sondage
- Acheter les données auprès de sociétés spécialisés
Il faut en collecter le plus possible.
II. Nettoyage#
Les données collectées ne sont presque jamais exploitables en l'état. Il peut s'agir d'erreurs ou de différence de format ou d'unités par exemple. Dans tous les cas, un peu de ménage est nécessaire.

Voici quelques opérations de nettoyage:
- Uniformiser les unités (des tailles exprimées en mètre ou en centimètres)
- Gérer les données manquantes
- Supprimer les données dupliquées
- Enlever les unités et garder les nombres (10Kg - 10)
À la fin de cette opération, les données doivent être cohérentes et plus ou moins exploitables.
III. Exploration#
L'objectif est de regarder de plus près les données dont on dispose et de s’assurer de la bonne qualité des données. Ce travail d’exploration permettra de découvrir les éventuelles aberrations dans les données.

- La distribution de la variable objectif
- La distribution des variables explicatives (différentes échelles de grandeur)
- Les corrélations entre les variables
Quelles sont les variables les plus pertinentes ?
Distribution des variables explicatives#
Le jeu de données est déséquilibré, les données malignes sont plus présentes.
Il faudra en tenir lors de l’échantillonnage.
Attention, ce déséquilibre peut être non conforme à la réalité.
Distribution des variables explicatives#
Les variables n'ont pas la même échelle de grandeur.
Dans la suite, il faudra les ramener toutes les variable à une échelle commune.
Corrélation entre les variables#
Il ne sert à rien de garder des variables corrélées entre elles. Elles apportent la même information.
area et perimeter sont les variables les plus corrélées. On peut envisager de garder q'une seule pour la modélisation.
Les variables les plus pertinentes#
Avec les variables area et smoothness, on a une bonne dispersion entre les
différentes classes.
Nous allons travailler avec uniquement ces deux variables dans un premier temps.
IV. Pré-traitement ou Transformation#
Conversion en valeurs numériques#
Les algorithmes de machine learning ne consomment que des chiffres et des nombres, il est donc nécessaire de convertir les valeurs non numériques (catégorielles) en numérique.

Dans notre exemple, M est encodé en 1 et B en 0.
Normalisation des données#
L'objectif de cette opération est de ramener toutes les variables à une échelle commune. Voici deux manières de procéder
- Normalisation (min, max)
- Standardisation (Centrage et Réduction)
Les variables ont désormais la même échelle de grandeur.
La normalisation accélère la convergence de la méthode d’optimisation d’où l’intérêt de normaliser les données. D’une part il faut plusieurs étapes pour atteindre le minimum et d’autre part en quelques itérations le minimum est atteint.
V. Échantillonnage#
Toutes les données ne vont pas servir à entraîner le modèle. Il faut procéder à un échantillonnage. En général, 80% ou 70% des données servent à estimer le modèle, ensuite les 20% ou 30% à l’évaluer afin de s’assurer que le modèle généralise correctement.
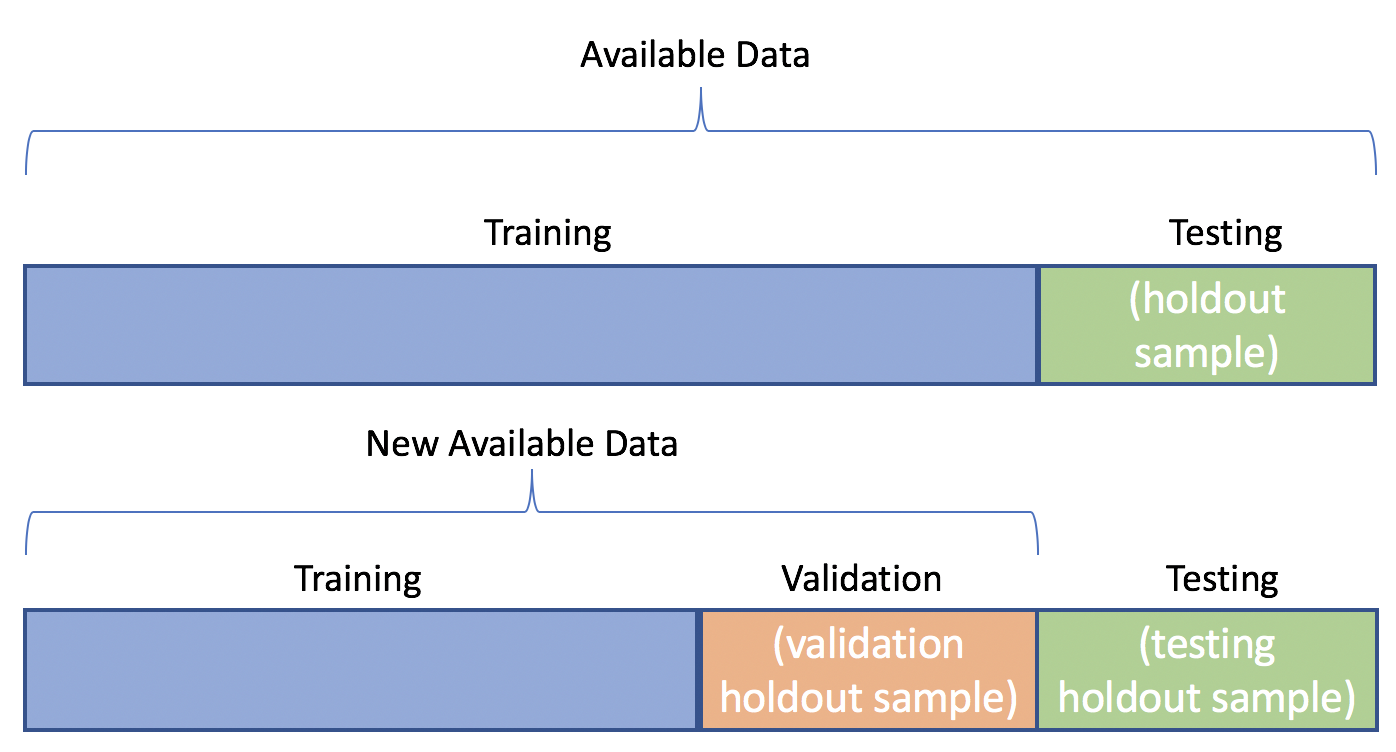
Il faut s’assurer que l’on garde la même distribution des classes dans les différentes partitions du jeu de données. Si la classe A représente 45% des données alors dans les partitions on doit avoir à peu près 45% de A.
VI. Modélisation ou Entraînement#
Un modèle est une fonction mathématique ou un ensemble de règles permettant d’attribuer une étiquette à une donnée nouvelle.
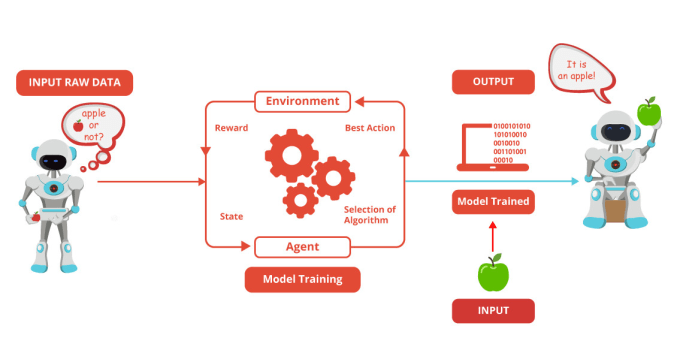
Ensemble de règles permettant d’attribuer une étiquette à une donnée. Il existe des modèles:
- paramétriques
- non-paramétriques (KNN)
Généralement, lors de la phase d'entraînement, on estime les valeurs de ces paramètres qui donnent les meilleures prédictions. En résumé le modèle permettra de prédire le diagnostic du patient.
VII. Évaluation#
Le but de l'évaluation est de s'assurer que le modèle généralise bien.

On dit qu’un modèle généralise bien si ses prédictions sur les données de test sont aussi bonnes que celles sur le jeu d’entraînement.
| Surapprentissage | Sous-apprentissage |
|---|---|
| Bonnes prédictions sur les données d'entraînement | Mauvaises prédictions sur les données d'entraînement |
| Mauvaises prédictions sur les données de test | Mauvaises prédictions sur les données de test |
Comment sélectionner le modèle final ?#
Après avoir essayé différentes approches, il faut à présent choisir la meilleure.
Ce choix se fait suivant un critère ou un score:
- Le taux de bonnes prédictions,
- La précision,
- La valeur de la fonction de coût...
Pour un problème de classification, le taux de bonnes prédictions est un bon critère. Mais attention si certaines sont surreprésentées.
Validation croisée#
Tester différentes valeurs des hyperparamètres et sélectionner la combinaison qui donne les meilleurs résultats.
- Partitionner le jeu de données
- Entraîner le modèle avec les différentes combinaisons
- Évaluer le modèle
- Sélectionner la combinaison qui obtient le meilleur résultat moyen
VIII. Déploiement#

Maintenant qu’on est satisfait des résultats de l'évaluation, on peut mettre le modèle en production, c’est bien l’objectif final du projet.

- Le modèle est exporté avec pickle
- Le modèles est exposé via une API (Flask ou FastAPI)
- Allez plus loin avec un interface web (Gradio)
Références#
IX. Maintenance ou Monitoring#
Il s'agit de suivre le comportement du modèle en production.