Prise en main de PySpark - Le guide ultime
Spark est une plateforme open-source de traitement de données volumineuses. Au fil des années, Spark s'est imposé comme l'outil de référence pour l'ingénierie de données. Dans ce guide ultime, je vous présente PySpark, l'API Python de Spark.

Installer Java#
Apache Spark étant dévelopée en Java, nous devons installer Java. Si vous l'avez déjà installé alors vous pouvez passer cette étape, sinon suivez ce tutoriel pour effectuer l'installation.
Pour Linux
Installer Java
Définir la variable d'environnement
Installer Apache Spark#
Installer Java
Rendez-vous à la page de télechargement Download Apache Spark™
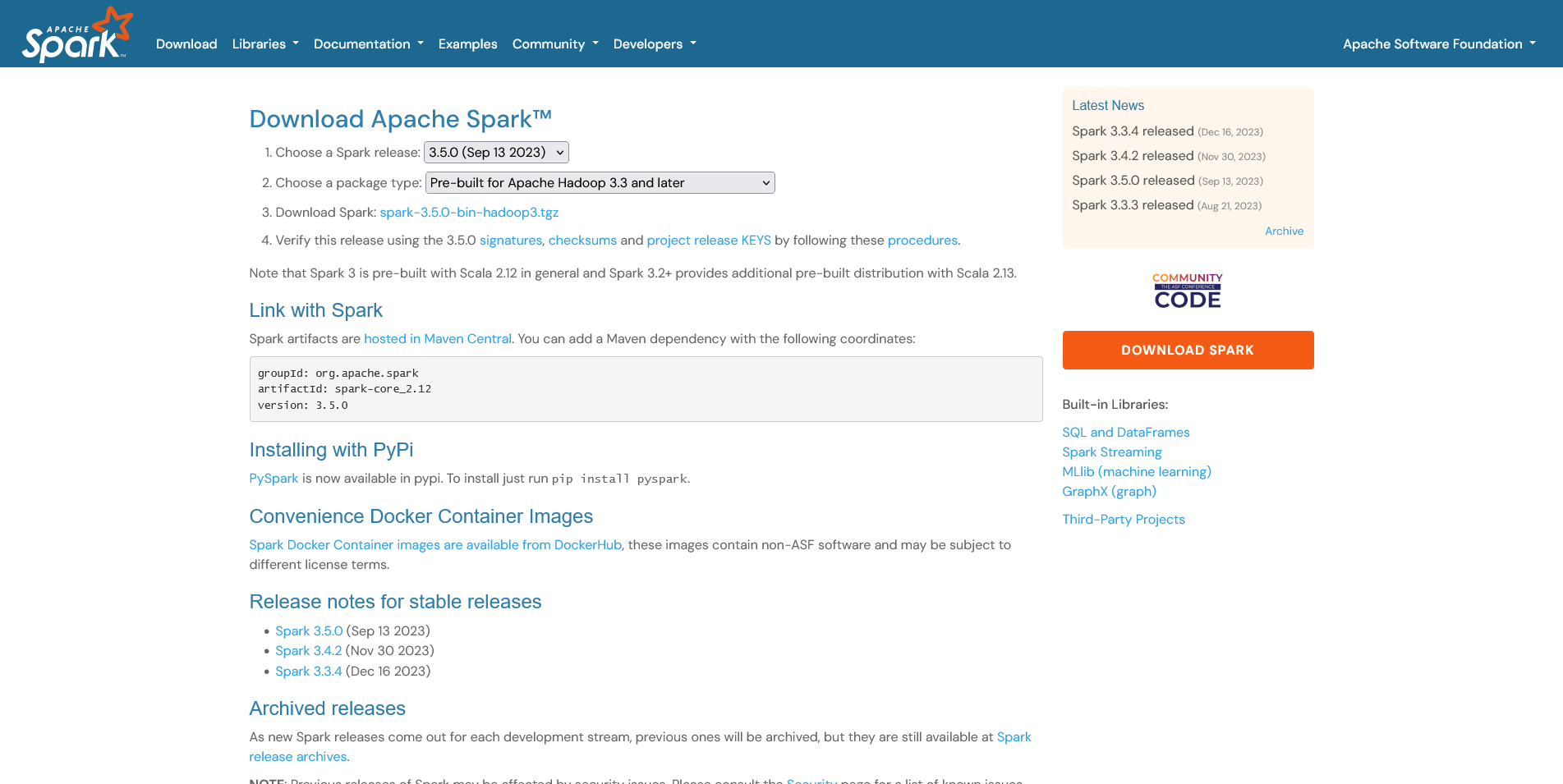
Définir la variable d'environnement
Démarrer Spark#
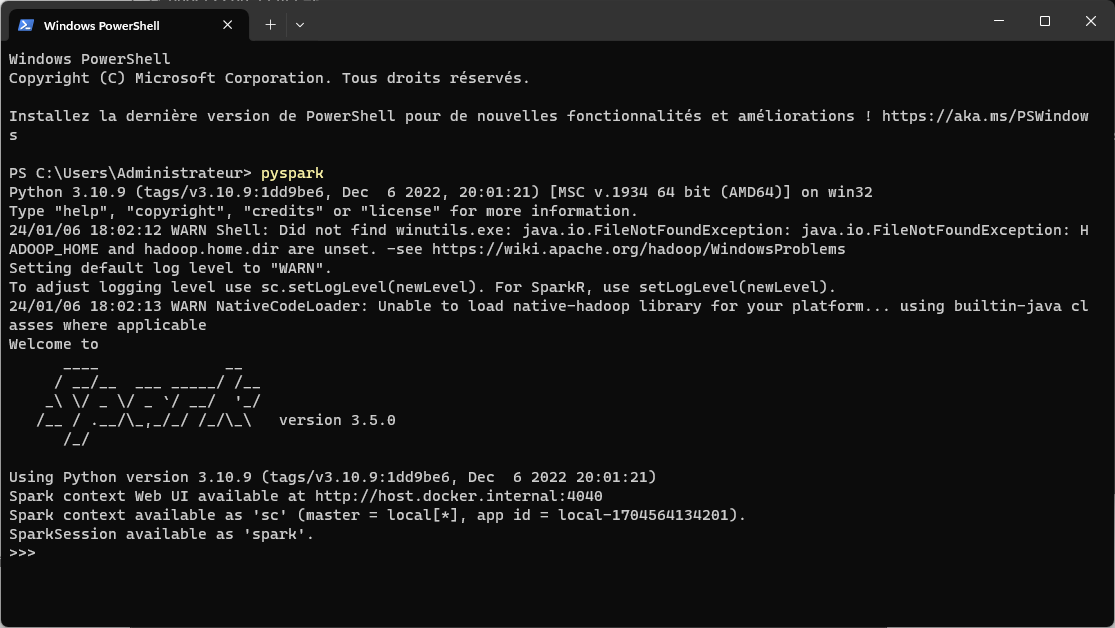
Ouvrez le terminal et lancez la commande suivante pyspark
Ouvrez le navigateur et rendez-vous à cette adresse http://host.docker.internal:4040
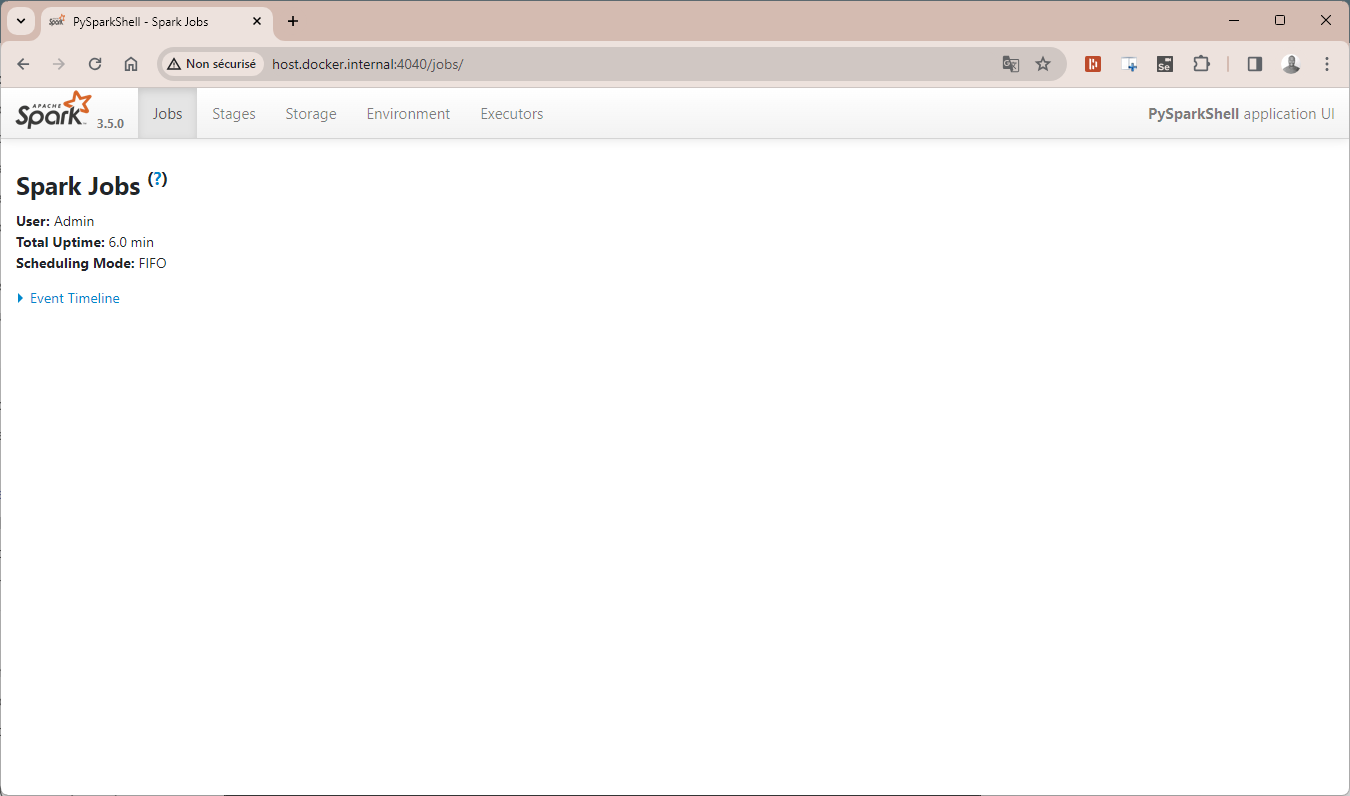
Parfait ! Le moteur Spark est opérationnel sur votre machine, il ne nous reste plus qu'à installer le package PySpark pour
Créer un environnement virtuel#
Lancez Anaconda Prompt et faites la commande suivante:
Cette commande va créer une environnement virtuel avec le nom spark, tapez y pour confirmer la création.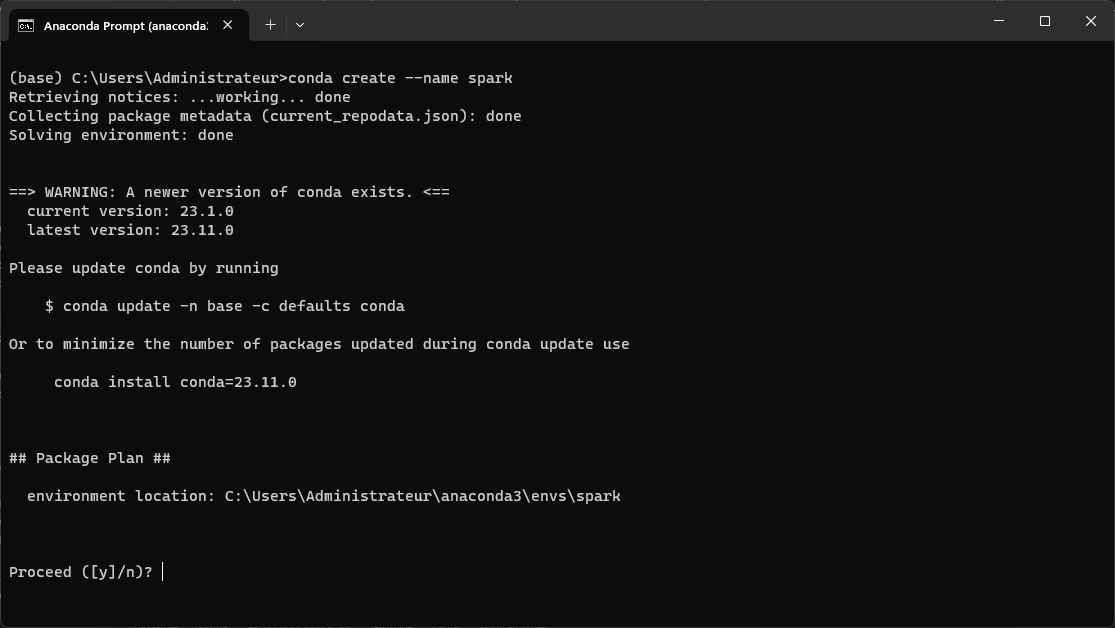
Une fois l'environnement virtuel créé, il faut l'activer avec la commande suivante.
Installer PySpark#
PySpark peut-être installé depuis le gestionnaire de packages Pypi. Pour cela tapez la commande suivante
Installer JupyterLab#
Les notebooks offrent un environnement interactif idéal pour travail avec PySpark.
Lancer JupyterLab#
Une fois l'installation terminée, lancez la commande suivante
Créez un notebook